Depth-First Search (DFS) in ABAP
Depth-First Search (DFS) is a classic algorithm used for traversing or searching tree or graph data structures. The algorithm starts at the root node (or an arbitrary node in the case of a graph) and explores as far as possible along each branch before backtracking. This guide will explain how to implement DFS in ABAP.
Understanding Depth-First Search
DFS works by exploring each possible path in a graph or tree until it reaches the end of that path, then it backtracks and explores the next path. This process continues until all nodes are visited.
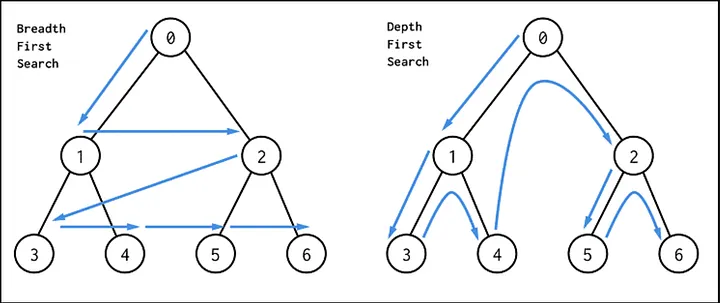
Characteristics of DFS:
- Memory Usage: DFS typically uses less memory than Breadth-First Search (BFS) because it doesn't need to store all child nodes at each level.
- Implementation: DFS can be implemented using recursion or an explicit stack.
Implementing DFS in ABAP
1. Recursive DFS
Recursive DFS is straightforward to implement. The algorithm recursively visits each adjacent node until it reaches a dead end.
-
Example Structure: Let's assume we have a simple graph represented by an adjacency list.
-
Recursive DFS Implementation:
REPORT Z_DFS.
CLASS lcl_graph DEFINITION.
PUBLIC SECTION.
TYPES: BEGIN OF ty_node,
id TYPE i,
adj_nodes TYPE TABLE OF i WITH EMPTY KEY,
END OF ty_node.
DATA: lt_graph TYPE TABLE OF ty_node,
lt_visited TYPE TABLE OF i WITH EMPTY KEY.
METHODS: add_edge IMPORTING iv_start TYPE i iv_end TYPE i,
dfs_recursive IMPORTING iv_node TYPE i.
ENDCLASS.
CLASS lcl_graph IMPLEMENTATION.
METHOD add_edge.
DATA: ls_start_node TYPE ty_node,
ls_end_node TYPE ty_node.
" Find start node in graph
READ TABLE lt_graph INTO ls_start_node WITH KEY id = iv_start.
IF sy-subrc <> 0.
" If start node does not exist, create it
CLEAR ls_start_node.
ls_start_node-id = iv_start.
APPEND ls_start_node TO lt_graph.
ENDIF.
" Add end node to the adjacency list of the start node
APPEND iv_end TO ls_start_node-adj_nodes.
" Update the graph
MODIFY lt_graph FROM ls_start_node TRANSPORTING adj_nodes WHERE id = iv_start.
" Assuming undirected graph, add back edge
READ TABLE lt_graph INTO ls_end_node WITH KEY id = iv_end.
IF sy-subrc <> 0.
CLEAR ls_end_node.
ls_end_node-id = iv_end.
APPEND ls_end_node TO lt_graph.
ENDIF.
APPEND iv_start TO ls_end_node-adj_nodes.
MODIFY lt_graph FROM ls_end_node TRANSPORTING adj_nodes WHERE id = iv_end.
ENDMETHOD.
METHOD dfs_recursive.
DATA: ls_node TYPE ty_node.
" Check if the node has already been visited
READ TABLE lt_visited WITH KEY table_line = iv_node TRANSPORTING NO FIELDS.
IF sy-subrc = 0.
RETURN. " Node already visited, exit the method
ENDIF.
" Mark the current node as visited
APPEND iv_node TO lt_visited.
" Output the current node
WRITE: / 'Visiting node:', iv_node.
" Find the node in the graph
READ TABLE lt_graph INTO ls_node WITH KEY id = iv_node.
" Explore all adjacent nodes
LOOP AT ls_node-adj_nodes INTO DATA(lv_adj_node).
dfs_recursive( iv_node = lv_adj_node ).
ENDLOOP.
ENDMETHOD.
ENDCLASS.
START-OF-SELECTION.
DATA: lo_graph TYPE REF TO lcl_graph.
CREATE OBJECT lo_graph.
" Initializing Graph
lo_graph->add_edge( iv_start = 1 iv_end = 2 ).
lo_graph->add_edge( iv_start = 1 iv_end = 3 ).
lo_graph->add_edge( iv_start = 2 iv_end = 4 ).
lo_graph->add_edge( iv_start = 3 iv_end = 4 ).
lo_graph->add_edge( iv_start = 4 iv_end = 5 ).
" Perform DFS from node 1
lo_graph->dfs_recursive( iv_node = 1 ).
Conclusion
Depth-First Search (DFS) is a fundamental algorithm that is easy to implement in ABAP. Whether using recursion or an explicit stack, DFS can be applied to various problems, such as finding paths in a graph, detecting cycles, or exploring all possible states. This guide provides the foundational knowledge needed to implement DFS in ABAP effectively. For more complex graphs or specific applications, you may need to extend or customize the basic DFS implementation.
Implementing Breadth-First Search (BFS) in ABAP
Breadth-First Search (BFS) is a fundamental graph traversal algorithm used to explore nodes and edges of a graph in a level-by-level manner. This guide provides an overview of how to implement BFS in ABAP, including code examples and explanations.
Overview of Breadth-First Search
BFS starts from a source node and explores all its neighbors at the current level before moving on to nodes at the next level. BFS is particularly useful for finding the shortest path in an unweighted graph or for traversing trees and graphs level by level.
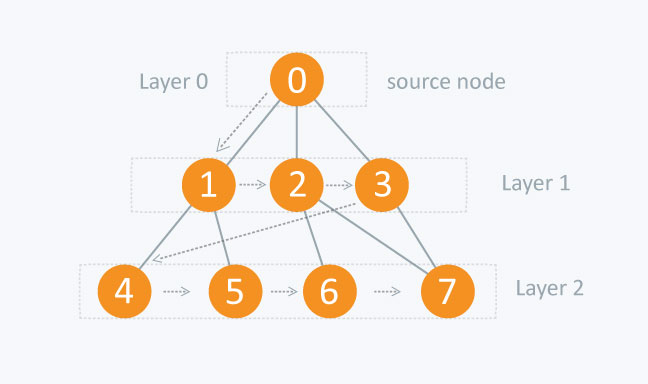
Key Concepts:
- Queue: BFS uses a queue data structure to keep track of nodes that need to be explored.
- Visited Nodes: A list or array is used to keep track of visited nodes to avoid processing a node more than once.
Example Use Case
Consider a scenario where you have a network of connected nodes (e.g., cities connected by roads), and you need to find the shortest path from one city to another.
Graph Representation
In ABAP, the graph can be represented using an internal table where each entry represents an edge between two nodes.
-
Graph Structure Example:
TYPES: BEGIN OF ty_edge, node1 TYPE string, node2 TYPE string, END OF ty_edge. DATA: lt_graph TYPE TABLE OF ty_edge, ls_edge TYPE ty_edge. " Sample graph edges ls_edge-node1 = 'A'. ls_edge-node2 = 'B'. APPEND ls_edge TO lt_graph. ls_edge-node1 = 'A'. ls_edge-node2 = 'C'. APPEND ls_edge TO lt_graph. ls_edge-node1 = 'B'. ls_edge-node2 = 'D'. APPEND ls_edge TO lt_graph. ls_edge-node1 = 'C'. ls_edge-node2 = 'D'. APPEND ls_edge TO lt_graph. ls_edge-node1 = 'D'. ls_edge-node2 = 'E'. APPEND ls_edge TO lt_graph.
BFS Implementation
The BFS algorithm can be implemented in ABAP using a loop and a queue (which can be simulated using an internal table).
-
Step-by-Step BFS:
- Initialize the queue with the starting node.
- Mark the starting node as visited.
- While the queue is not empty:
- Dequeue a node from the front of the queue.
- Process the node (e.g., check if it's the destination).
- Enqueue all unvisited neighboring nodes.
- Mark the neighbors as visited.
-
ABAP Code Example:
REPORT z_bfs_example.
TYPES: BEGIN OF ty_edge,
node1 TYPE string,
node2 TYPE string,
END OF ty_edge.
DATA: lt_graph TYPE TABLE OF ty_edge,
ls_edge TYPE ty_edge,
lt_queue TYPE TABLE OF string,
lv_node TYPE string,
lt_visited TYPE TABLE OF string.
" Sample graph edges
ls_edge-node1 = 'A'. ls_edge-node2 = 'B'. APPEND ls_edge TO lt_graph.
ls_edge-node1 = 'A'. ls_edge-node2 = 'C'. APPEND ls_edge TO lt_graph.
ls_edge-node1 = 'B'. ls_edge-node2 = 'D'. APPEND ls_edge TO lt_graph.
ls_edge-node1 = 'C'. ls_edge-node2 = 'D'. APPEND ls_edge TO lt_graph.
ls_edge-node1 = 'D'. ls_edge-node2 = 'E'. APPEND ls_edge TO lt_graph.
" Starting node
APPEND 'A' TO lt_queue.
APPEND 'A' TO lt_visited.
WHILE lt_queue IS NOT INITIAL.
" Dequeue the front node
READ TABLE lt_queue INTO lv_node INDEX 1.
DELETE lt_queue INDEX 1.
" Process the current node
WRITE: / 'Processing node:', lv_node.
" Enqueue unvisited neighbors
LOOP AT lt_graph INTO ls_edge WHERE node1 = lv_node OR node2 = lv_node.
DATA: lv_neighbor TYPE string.
IF ls_edge-node1 = lv_node.
lv_neighbor = ls_edge-node2.
ELSE.
lv_neighbor = ls_edge-node1.
ENDIF.
" Check if the neighbor has already been visited
READ TABLE lt_visited WITH KEY table_line = lv_neighbor TRANSPORTING NO FIELDS.
IF sy-subrc <> 0.
APPEND lv_neighbor TO lt_queue.
APPEND lv_neighbor TO lt_visited.
ENDIF.
ENDLOOP.
ENDWHILE.
Explanation:
- Graph Representation: The graph is represented as a list of edges, where each edge connects two nodes.
- Queue (lt_queue): The queue stores nodes that need to be explored.
- Visited Nodes (lt_visited): This table keeps track of nodes that have already been visited to prevent revisiting.
- Processing Nodes: The BFS algorithm processes nodes by dequeuing them from the front of the queue and enqueuing their unvisited neighbors.
Use Cases for BFS in ABAP
- Finding the Shortest Path: BFS is ideal for finding the shortest path in unweighted graphs, such as navigating customer relationships or supply chains.
- Level Order Traversal: BFS is used for level-order traversal in tree structures, which can be useful in hierarchical data processing.
- Network Analysis: BFS can be applied to analyze networks of connected entities, such as business partners or organizational structures.
Conclusion
Breadth-First Search (BFS) is a powerful algorithm for traversing graphs and trees. This guide provides a basic implementation in ABAP, which can be extended and adapted for various use cases. For more complex scenarios, such as weighted graphs, consider using more advanced algorithms like Dijkstra's or A*.
This implementation can serve as a foundation for solving a wide range of problems related to graph traversal in SAP systems.
Implementing Binary Search in ABAP
Binary Search is an efficient algorithm for finding an item from a sorted list of items. It works by repeatedly dividing the search interval in half. If the value of the search key is less than the item in the middle of the interval, the interval is narrowed to the lower half. Otherwise, it is narrowed to the upper half. This process continues until the value is found or the interval is empty.
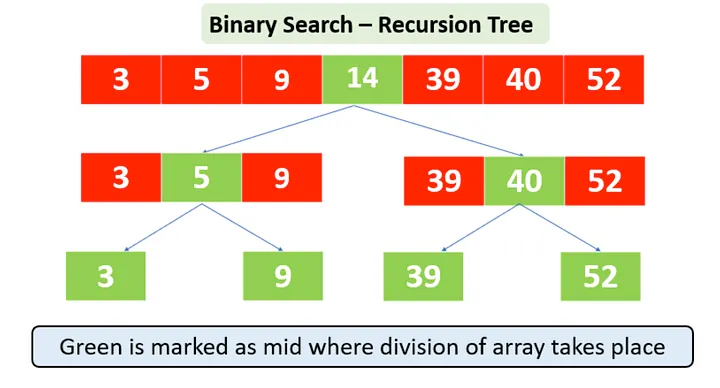
Overview of Binary Search
- Precondition: The list or array must be sorted.
- Time Complexity: O(log n), where n is the number of elements in the list.
- Space Complexity: O(1) for the iterative approach.
Example Use Case
Consider a scenario where you have a sorted list of customer IDs and you need to find the position of a specific customer ID in the list.
Binary Search Implementation
Binary search can be implemented in ABAP using a loop to repeatedly narrow the search range based on comparisons.
-
Step-by-Step Binary Search:
- Initialize the start and end pointers.
- Find the middle element of the current search range.
- Compare the middle element with the target value:
- If it matches, the search is complete.
- If the target is less than the middle element, narrow the search to the lower half.
- If the target is greater than the middle element, narrow the search to the upper half.
- Repeat until the target value is found or the search range is empty.
-
ABAP Code Example:
REPORT z_binary_search_example.
DATA: lt_customers TYPE TABLE OF i,
lv_target TYPE i,
lv_start TYPE i,
lv_end TYPE i,
lv_mid TYPE i,
lv_found TYPE i VALUE 0.
" Sample sorted list of customer IDs
lt_customers = VALUE #( ( 101 ) ( 203 ) ( 305 ) ( 407 ) ( 509 ) ( 611 ) ( 713 ) ).
" Target customer ID to search for
lv_target = 407.
lv_start = 1.
lv_end = LINES( lt_customers ).
WHILE lv_start <= lv_end.
lv_mid = lv_start + ( lv_end - lv_start ) / 2.
READ TABLE lt_customers INDEX lv_mid INTO DATA(lv_value).
IF lv_value = lv_target.
lv_found = lv_mid.
EXIT.
ELSEIF lv_value < lv_target.
lv_start = lv_mid + 1.
ELSE.
lv_end = lv_mid - 1.
ENDIF.
ENDWHILE.
IF lv_found > 0.
WRITE: / 'Customer ID', lv_target, 'found at position', lv_found.
ELSE.
WRITE: / 'Customer ID', lv_target, 'not found in the list'.
ENDIF.
Explanation:
- Sorted List (lt_customers): The list of customer IDs is sorted, which is a prerequisite for binary search.
- Start and End Pointers:
lv_startandlv_endrepresent the current range of indices being searched. - Middle Index (lv_mid): The middle index of the current range is calculated to check if it matches the target value.
- Comparison: Depending on whether the middle value is greater or less than the target, the search range is adjusted accordingly.
- Exit Condition: The loop continues until the target is found or the search range becomes empty (
lv_start>lv_end).
Use Cases for Binary Search in ABAP
- Searching in Sorted Data: Binary search is ideal for searching in large, sorted datasets, such as sorted tables or arrays.
- Optimizing Search Operations: Binary search is more efficient than linear search for large datasets, making it useful for performance-critical applications.
- Finding Specific Entries: Binary search can be used in scenarios where specific entries in sorted data need to be found quickly, such as searching for specific order numbers, customer IDs, or product codes.
Conclusion
Binary Search is a fundamental algorithm that provides efficient search capabilities in sorted data. This guide provides an implementation of binary search in ABAP, which can be adapted for various use cases. Understanding and implementing binary search is essential for optimizing search operations in your ABAP programs.